

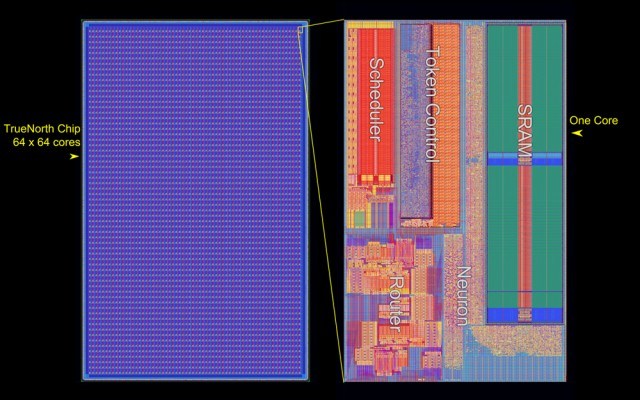
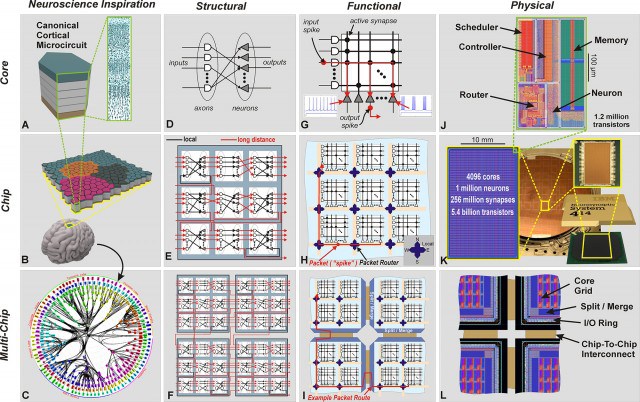
The new chip developed by IBM has 4096 cores, 1 million programmable neurons, and 5.4 billion transistors, heralding what some are calling a new era in computing.
The chip, called TrueNorth, is the most advanced neuromorphic (brain-like) chip created, and is incredibly efficient.
The chip consumes only 72 milliwatts at maximum load–equivalent to 400 billion synaptic operations per second per watt. The chip is therefore around 180,000 times more efficient than a modern CPU, and almost 800 times more efficient than other cutting-edge neuromorphic approaches.
Spokespeople for IBM commented on the TrueNorth chip, “One of the key problems with developing a new chip based on a novel architecture is that you also have to create developer tools and software that actually make efficient use of those thousands of cores and billions of synapses. Fortunately, IBM’s already got that covered: Last year it released a specialized programming language (Corelet) and simulator (Compass) that let you program and test your neuromorphic programs before running them on actual hardware.”
“Ultimately, the main purpose of the SyNAPSE project is to take existing systems that simulate the functionality of the brain in software — such as deep neural networks — and run them on hardware that was specifically designed for the task. As you may already know, dedicated hardware tends to orders of magnitude more efficient than simulating/emulating the hardware in software on a general-purpose CPU. This is why IBM is touting some utterly incredible efficiency figures for TrueNorth. For neural networks with high spike rates and a large number of active synapses, TrueNorth can deliver 400 billion synaptic operations per second (SOPS) per watt. When running the exact same neural network, a general-purpose CPU is 176,000 times less energy efficient, while a state-of-the-art multiprocessor neuromorphic system (48 chips, each with 18 cores) is 769 times less efficient. While it’s not directly comparable, the world’s most efficient supercomputer only manages around 4.5 billion FLOPS per watt.
“I don’t think IBM is actually getting back into the consumer electronics market (though that would be amusing). Rather, this is just a concept of the kind of thing the TrueNorth chip might one day enable.”
A technical reserach paper was published in Science today, titled “A million spiking-neuron integrated circuit with a scalable communication network and interface.”
By Andy Stern
A great comment about this article by Esadatari on another forum:
I think that, once adopted by early adopters, yes, yes it will be [“a new era in computing”].
CPU architecture has not significantly changed in forever. We may innovate upon already existing standards, but a new type of CPU has not really been introduced into the mix that really changes the way information is processed. This new CPU, while still in its infancy stages, approaches data computation in a much different way.
If this takes off, it will absolutely reshape the way information is processed, and will this be a new era in computing.
Trust me when I say that I’m used to sensationalist bullshit and click bait; this is an advancement that is actually worth the hype. That’s both from a technology standpoint and a neuroscience standpoint!
There will be some inaccuracies in here, but the jist of it is this: the way the brain works is a distributed pattern recognition database, where each node (neuron) that is actively used in recalling a pattern will play out. Imagine all the neurons used to recall letters. Is it a round letter or a straight/sharp letter? If round, is it missing a portion of it? (c) Is it adding another straight line on? (a) So each one of these neurons is recalling a specific portion of the pattern as it applies. The interesting thing is that if certain portions of the pattern are matched, it increases the likelihood of the higher or lower level patterns being matched (the opposite is also true for sending a signal block if the pattern is not matched).
So when comparing to CPUs in status quo tech used in PCs, you could imagine a ton of people waiting in a line to go to destination X. As more new people arrive, they have to get in line and wait in a waiting pool area. These people are individual computations that make up a larger computation as part of a program or insert a myriad of other uses here. At first, there was only one Kiosk that these people could go through, one at a time. Then we made it more advanced and gave them 2 kiosks to pass through. Then 4 kiosks, then 8. The way they move through the kiosks may be a little more efficient, there may even be more kiosks added, but overall, they still move in a single file line to go through a kiosk before moving on.
This processor would have hundreds of thousands of kiosks, all of which can lead to other kiosks, and this stream of people can now be auto-sorted into kiosks that match their particular needs at that moment. New in town? Go to this one specific kiosk amidst thousands of other kiosks, he’ll know exactly how to deal with you. Not your first rodeo and you’ve done this a million times before? Go to the kiosk you always go to. Those kiosks feed into higher level kiosks that only deal with certain lower level kiosks. The end result is that the individual people got processed at a kiosk much much faster. In fact, its likely that these people will be processed at the rate in which they are presented to the kiosk system; no waiting pool will ever come into use. If one is to be used, it’ll be emptied a lot faster because of the distributed matching.